COVID and the base rate fallacy
Should we be concerned that vaccinated people are getting COVID?
I’ve spoken to people who’re worried that the COVID vaccines aren’t effective because some vaccinated people catch COVID and are hospitalized. Let’s look at the claim and see if it stands up to analysis.
Let's start with some facts:
- Vaccines aren’t 100% effective for 100% of people. For example, the smallpox vaccine is 95% effective at preventing infection (https://www.health.ny.gov/publications/7022/).
- Even if vaccines don’t prevent infection, they can reduce the severity of symptoms (e.g. https://www.cdc.gov/flu/vaccines-work/vaccineeffect.htm).
- Vaccines slow or prevent the spread of disease by providing fewer hosts for infection – in other words, herd immunity (https://www.mayoclinic.org/diseases-conditions/coronavirus/in-depth/herd-immunity-and-coronavirus/art-20486808)
- Medical tests aren’t 100% effective either; there are false positives and false negatives.
- False positives mean the test says positive when really you’re negative.
- False negatives mean the test says you’re negative when really you’re positive.
Marc Rummy’s diagram
Marc Rummy created this diagram to explain what’s going on with COVID hospitalizations. He’s made it free to share, which is fantastic.
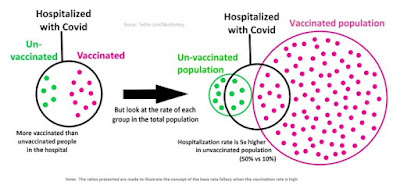
In this diagram, the majority of the population is vaccinated (91%). The hospitalization rate for the unvaccinated is 50% but for the vaccinated, it’s 10%. If the total population is 110, this leads to 5 unvaccinated people hospitalized and 10 vaccinated people hospitalized - in other words, 2/3 of those in hospital with COVID have been vaccinated.
Explaining the result
Let’s imagine we just looked at hospitalizations: 5 unvaccinated and 10 vaccinated. This makes it look like vaccinations aren’t working – after all, the majority of people in hospital are vaccinated. You can almost hear ignorant journalists writing their headlines now (“Questions were raised about vaccine effectiveness when the health minister revealed the majority of patients hospitalized had been vaccinated.”). But you can also see anti-vaxxers seizing on these numbers to try and make a point about not getting vaccinated.
The reason why the numbers are the way they are is because the great majority of people are vaccinated.
Let’s look at three different scenarios with the same population of 110 people and the same hospitalization rates for vaccinated and unvaccinated:
- 0% vaccinated – 55 people hospitalized
- 91% vaccinated – 15 people hospitalized
- 100% vaccinated – 11 people hospitalized
Clearly, vaccinations reduce the number of hospitalizations. The anti-vaccine argument seems to be, if it doesn't reduce the risk to zero, it doesn't work - which is a strikingly weak and ignorant argument.
In this example, vaccination doesn’t reduce the risk of infection to zero, it reduces it by a factor of 5. In the real world, vaccination reduces the risk of infection by 5x and the risk of death due to COVID by 13x (https://www.nytimes.com/interactive/2021/us/covid-cases.html). The majority of people hospitalized now appear to be unvaccinated even though vaccination rates are only just above 60% in most countries (https://www.nytimes.com/interactive/2021/world/covid-cases.html, https://www.masslive.com/coronavirus/2021/09/breakthrough-covid-cases-in-massachusetts-up-to-about-40-while-unvaccinated-people-dominate-hospitalizations.html).
The bottom line is very simple: if you want to reduce your risk of hospitalization and protect your family and community, get vaccinated.
The base rate fallacy
The mistake the anti-vaxxers and some journalists are making is a very common one, it’s called the base rate fallacy (https://thedecisionlab.com/biases/base-rate-fallacy/). There are lots of definitions online, so I’ll just attempt a summary here: “the base rate fallacy is where someone draws an incorrect conclusion because they didn’t take into account the base rate in the general population. It’s especially a problem for conditional probability problems.”
Let’s use another example from a previous blog post:
“Imagine there's a town of 10,000 people. 1% of the town's population has a disease. Fortunately, there's a very good test for the disease:
- If you have the disease, the test will give a positive result 99% of the time (sensitivity).
- If you don't have the disease, the test will give a negative result 99% of the time (specificity).
You go into the clinic one day and take the test. You get a positive result. What's the probability you have the disease?”
The answer is 50%.
The reason why the answer is 50% and not 99% is because 99% of the town’s population does not have the disease (the base rate), which means half of the positives will be false positives.
What’s to be done?
Conditional probability (for example, the COVID hospitalization data) is screwy and can sometimes seem counter to common sense. The general level of statistical (and probability) knowledge in the population is poor. This leaves people trying to make sense of the data around them but without the tools to do it, so no wonder they’re confused.
It’s probably time that all schoolchildren are taught some basic statistics. This should include some counter-intuitive results (for example, the disease example above). Even if very few schoolchildren grow up to analyze data, it would be beneficial for society if more people understood that interpreting data can be hard and that sometimes surprising results occur – but that doesn’t make them suspicious or wrong.
More importantly, journalists need to do a much better job of telling the truth and explaining the data instead of chasing cheap clicks.





























{kind=link}
.jpg){kind=link}
_(5092283927).jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_(14586331758).jpg){kind=link}
{kind=link}