The post-hoc fallacy
Over my career, I’ve seen companies make avoidable business mistakes that’ve cost them significant time and money. Some of these mistakes happened because people have misunderstood “the rules of evidence” and they’ve made a classic post-hoc blunder. This error is insidious because it comes in different forms and it can seem like the error is the right thing to do.
In this blog post, I’ll show you how the post-hoc error can manifest itself in business, I’ll give you a little background on it, and show you some real-world examples, finally, I’ll show you how you can protect yourself.
A fictitious example to get us started
Imagine you’re an engineer working for a company that makes conveyor belts used in warehouses. A conveyor belt break is both very dangerous and very costly; it can take hours to replace, during which time at least part of the warehouse is offline. Your company thoroughly instruments the belts and there’s a vast amount of data on belt temperature, tension, speed, and so on.
Your Japanese distributor tells you they’ve noticed a pattern. They’ve analyzed 319 breaks and found that in 90% of cases, there’s a temperature spike 15 minutes before the break. They’ve sent you the individual readings which look something like the chart below.
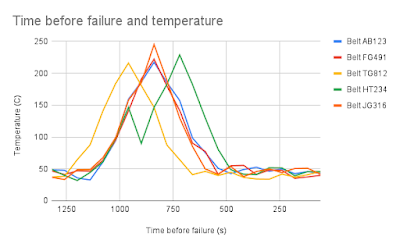
The distributor is demanding that you institute a new control that stops the belt if a temperature spike is detected and prompts the customer to replace the belt.
Do you think the Japanese distributor has a compelling case? What should you do next?
The post-hoc fallacy
The full name of this fallacy is “post hoc ergo propter hoc”, which is thankfully usually shortened to "post-hoc". The fallacy goes like this:
- Event X happens then event Y happens
- Therefore, X caused Y.
The oldest example is the rooster crowing before dawn: “the rooster crows before dawn, therefore the rooster’s crow causes the dawn”. Obviously, this is a fallacy and it’s easy to spot.
Here's a statement using the same logic to show you that things aren’t simple: “I put fertilizer on my garden, three weeks later my garden grew, therefore the fertilizer caused my garden to grow”. Is this statement an error?
As we’ll see, statements of the form:
- Event X happens then event Y happens
- Therefore, X caused Y.
Aren’t enough of themselves to provide proof.
Classic post-hoc errors
Hans Zinsser in his book “Rats, lice, and history” tells the story of how in medieval times, lice were considered a sign of health in humans. When lice left a person, the person became sick or died, so the obvious implication is that lice are necessary for health. In reality, of course, lice require a live body to feed on and a sick or dead person doesn’t provide a good meal.
In modern times, something similar happened with violent video games. The popular press set up a hue and cry that playing violent video games led to violent real-life behavior in teenagers, the logic being that almost every violent offender had played violent video games. In reality, a huge fraction of the teenage population has played violent video games. More careful studies showed no effect.
Perhaps the highest profile post-hoc fallacy in modern times is vaccines and autism. The claim is that a child received a vaccine, and later on, the child was diagnosed with autism, therefore the vaccine caused autism. As we know, the original claims of a link were deeply flawed at best.
Causes of errors
Confounders
A confounder is something, other than the effect you’re studying, that could cause the results you’re seeing. The classic example is storks in Copenhagen after the second world war. In the 12-year period after the second world war, the number of storks seen near Copenhagen increased sharply, as did the number of (human) babies. Do we conclude storks cause babies? The cause of the increase in the stork population, and the number of babies, was the end of the second world war so the confounder here was war recovery.
In the autism case, confounders are everywhere. Both vaccinations and autism increased at the same time, but lots of other things changed at the same time too:
- Medical diagnosis improved
- Pollution increased
- The use of chemical cleaning products in the home increased
- Household income went up (but not for everyone, some saw a decrease)
- Car ownership went up.
Without further evidence, we can’t say what caused autism. Once again, it’s not enough of itself to say “X before Y therefore X causes Y”.
Confounders can be very, very hard to find.
Biased data
The underlying data can be so biased that it renders subsequent analysis unreliable. A good example is US presidential election opinion polling in 2016 and 2020; these polls under-represented Trump’s support, either because the pollsters didn’t sample the right voters or because Trump voters refused to be included in polls. Whatever the cause, the pollsters’ sampling was biased, which meant that many polls didn't accurately forecast the result.
For our conveyor belt example, the data might be just Japanese installations, or it might be Asian installations, or it might be worldwide. It might even be just data on broken belts, which introduces a form of bias called survivor bias. We need to know how the data was collected.
Thinking correlation = causation
Years ago, I had a physics professor who tried to beat into us students the mantra “correlation is not causation” and he was right. I’ve written about correlation and causation before, so I’m not going to say too much here. For causation to exist, there must be correlation, but correlation of itself does not imply causation.
To really convince yourself that correlation != causation, head on over to the spurious correlations website where you’ll find lots of examples of correlations that plainly don’t have an X causes Y relationship. What causes the correlation? Confounders, for example, population growth will lead to increases in computer science doctorates and arcade revenue.
Protections
Given all this, how can you protect yourself against the post-hoc fallacy? There are a number of methods designed to remove the effects of confounders and other causes of error.
Counterexamples
Perhaps the easiest way of fighting against post-hoc errors is to find counterexamples. If you think the rooster crowing causes dawn, then a good test is to shoot the rooster; if the rooster doesn’t crow and the dawn still happens, then the rooster can’t cause dawn. In the human lice example, finding a population of humans who were healthy and did not have lice would disprove the link between health and lice.
Control groups
Control groups are very similar to counterexamples. The idea is that you split the population you’re studying into two groups with similar membership. One group is exposed to a treatment (the treatment group) and the other group (the control group) is not. Because the two groups are similar, any difference between the groups must be due to the treatment.
I talked earlier about a fertilizer example: “I put fertilizer on my garden, three weeks later my garden grew, therefore the fertilizer caused my garden to grow”. The way to prove the fertilizer works is to split my garden into two equivalent areas, one area gets the fertilizer (the treatment group) and the other (the control group) does not. This type of agricultural test was the predecessor of modern randomized control trials and it’s how statistical testing procedures were developed.
RCTs (A/B testing)
How do you choose membership of the control and treatment groups? Naively, you would think the best method is to carefully select membership to make the two groups the same. In practice, this is a bad idea because there’s always some key factor you’ve overlooked and you end up introducing bias. It turns out random group assignment is a much, much better way.
A randomized control trial (RCT) randomly allocates people to either a control group or a treatment group. The treatment group gets the treatment, and the control group doesn’t.
Natural experiments
It’s not always possible to randomly allocate people to control and treatment groups. For example, you can’t randomly allocate people to good weather or bad weather. But in some cases, researchers can examine the impact of a change if group allocation is decided by some external event or authority. For example, a weather pattern might dump large amounts of snow on one town but pass by a similar nearby town. One US state might pass legislation while a neighboring state might not. This is called a natural experiment and there’s a great deal of literature on how to analyze them.
Matching, cohorts, and difference-in-difference
If random assignment isn’t possible, or the treatment event happened in the past, there are other analysis techniques you can use. These fall into the category of quasi-experimental methods and I’m only going to talk through one of them: difference-in-difference.
Difference-in-difference typically has four parts:
- Split the population into a treatment group (that received the treatment) and a control group (that did not).
- Split the control and treatment groups into multiple cohorts (stratification). For example, we could split by income levels, health indicators, or weight bands. Typically, we choose multiple factors to stratify the data.
- Match cohorts between the control and treatment groups.
- Observe how the system evolves over time, before and after the treatment event.
Assignment of the test population to cohorts is sometimes based on random selection from the test population if the population is big enough.
Previously, I said random assignment to groups out-performs deliberate assignment and it’s true. The stratification and cohort membership selection process in difference-in-difference is trying to make up for the fact we can’t use random selection. Quasi-experimental methods are vulnerable to confounders and bias; it’s the reason why RCTs are preferred.
Our fictitious example revisited
The Japanese distributor hasn't found cause and effect. They’ve found an interesting relationship that might indicate cause. They’ve found the starting point for investigation, not a reason to take action. Here are some good next steps.
What data did they collect and how did they collect it? Was it all the data, or was it a sample (e.g. Japan only, breakages only, etc.)? By understanding how the data was collected or sampled, we can understand possible alternative causes of belt breaks.
Search for counterexamples. How many temperature spikes didn’t lead to breaks? They found 287 cases where there was a break after a temperature spike, but how many temperature spikes were there? If there were 293 temperature spikes, it would be strong evidence that temperature spikes were worth investigating. If there were 5,912 temperature spikes, it would suggest that temperature wasn’t a good indicator.
Look for confounders. Are there other factors that could explain the result (for example, the age of the belt)?
Attempt a quasi-experimental analysis using a technique like difference-in-difference.
If this sounds like a lot of work requiring people with good statistics skills, that’s because it does. The alternative is to either ignore the Japanese distributor’s analysis (which might be true) or implement a solution (to a problem that might not exist). In either case, the cost of a mistake is likely far greater than the cost of the analysis.
Proving causality
Proving cause and effect is a fraught area. It’s a witches’ brew of difficult statistics, philosophy, and politics. The statistics are hard, meaning that few people in an organization can really understand the strength and weaknesses of an analysis. Philosophically, proving cause and effect is extremely hard and we’re left with probabilities of correctness, not the certainty businesses want. Politics is the insidious part; if the decision-makers don’t understand statistics and don’t understand the philosophy of causality, then the risk is decisions made on feelings not facts. This can lead to some very, very costly mistakes.
The post-hoc error is just one type of error you encounter in business decision-making. Regrettably, there are many other kinds of errors.
.jpg/640px-Watkin_Tree_stump_(480420361).jpg)









.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}